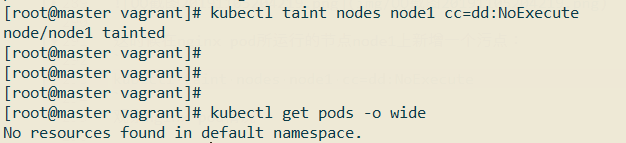
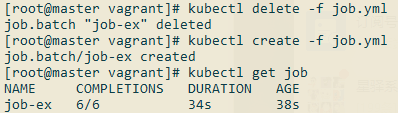
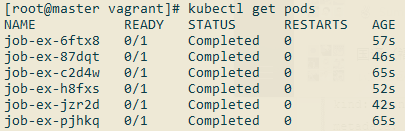
---
# Service account the client will use to reset the deployment,
# by default the pods running inside the cluster can do no such things.
kind: ServiceAccount
apiVersion: v1
metadata:
name: deployment-restart
namespace: <YOUR NAMESPACE>
---
# allow getting status and patching only the one deployment you want
# to restart
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: deployment-restart
namespace: <YOUR NAMESPACE>
rules:
- apiGroups: ["apps", "extensions"]
resources: ["deployments"]
resourceNames: ["<YOUR DEPLOYMENT NAME>"]
verbs: ["get", "patch", "list", "watch"] # "list" and "watch" are only needed
# if you want to use `rollout status`
---
# bind the role to the service account
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: deployment-restart
namespace: <YOUR NAMESPACE>
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: deployment-restart
subjects:
- kind: ServiceAccount
name: deployment-restart
namespace: <YOUR NAMESPACE>
cronjob配置:
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: deployment-restart
namespace: <YOUR NAMESPACE>
spec:
concurrencyPolicy: Forbid
schedule: '0 8 * * *' # cron spec of time, here, 8 o'clock
jobTemplate:
spec:
backoffLimit: 2 # this has very low chance of failing, as all this does
# is prompt kubernetes to schedule new replica set for
# the deployment
activeDeadlineSeconds: 600 # timeout, makes most sense with
# "waiting for rollout" variant specified below
template:
spec:
serviceAccountName: deployment-restart # name of the service
# account configured above
restartPolicy: Never
containers:
- name: kubectl
image: bitnami/kubectl # probably any kubectl image will do,
# optionaly specify version, but this
# should not be necessary, as long the
# version of kubectl is new enough to
# have `rollout restart`
command:
- 'kubectl'
- 'rollout'
- 'restart'
- 'deployment/<YOUR DEPLOYMENT NAME>'
[root@docker-master ~]# mkdir /app/wwwroot -p
[root@docker-master ~]# docker run -itd --name=nginx-test --mount type=bind,src=/app/wwwroot,dst=/usr/share/nginx/html nginx
453be5dc46e410c3daa5c34f219ed5d195c134a538b2e5f85d0c1d333fd7e7ff
[root@docker-master ~]# docker exec -it nginx-test bash
root@453be5dc46e4:/# mount
/dev/mapper/docker-8:2-528671-5a0afb1cab58d9e41d9ec2ecfc57b7045452918f77a15ede38aa9acb69d7bdac on / type xfs (rw,relatime,nouuid,attr2,inode64,logbsize=64k,sunit=128,swidth=128,noquota)
proc on /proc type proc (rw,nosuid,nodev,noexec,relatime)
tmpfs on /dev type tmpfs (rw,nosuid,size=65536k,mode=755)
devpts on /dev/pts type devpts (rw,nosuid,noexec,relatime,gid=5,mode=620,ptmxmode=666)
sysfs on /sys type sysfs (ro,nosuid,nodev,noexec,relatime)
tmpfs on /sys/fs/cgroup type tmpfs (ro,nosuid,nodev,noexec,relatime,mode=755)
cgroup on /sys/fs/cgroup/systemd type cgroup (ro,nosuid,nodev,noexec,relatime,xattr,release_agent=/usr/lib/systemd/systemd-cgroups-agent,name=systemd)
cgroup on /sys/fs/cgroup/hugetlb type cgroup (ro,nosuid,nodev,noexec,relatime,hugetlb)
cgroup on /sys/fs/cgroup/cpuset type cgroup (ro,nosuid,nodev,noexec,relatime,cpuset)
cgroup on /sys/fs/cgroup/net_cls type cgroup (ro,nosuid,nodev,noexec,relatime,net_cls)
cgroup on /sys/fs/cgroup/blkio type cgroup (ro,nosuid,nodev,noexec,relatime,blkio)
cgroup on /sys/fs/cgroup/devices type cgroup (ro,nosuid,nodev,noexec,relatime,devices)
cgroup on /sys/fs/cgroup/freezer type cgroup (ro,nosuid,nodev,noexec,relatime,freezer)
cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (ro,nosuid,nodev,noexec,relatime,cpuacct,cpu)
cgroup on /sys/fs/cgroup/perf_event type cgroup (ro,nosuid,nodev,noexec,relatime,perf_event)
cgroup on /sys/fs/cgroup/memory type cgroup (ro,nosuid,nodev,noexec,relatime,memory)
mqueue on /dev/mqueue type mqueue (rw,nosuid,nodev,noexec,relatime)
/dev/sda2 on /etc/resolv.conf type ext4 (rw,relatime,data=ordered)
/dev/sda2 on /etc/hostname type ext4 (rw,relatime,data=ordered)
/dev/sda2 on /etc/hosts type ext4 (rw,relatime,data=ordered)
shm on /dev/shm type tmpfs (rw,nosuid,nodev,noexec,relatime,size=65536k)
/dev/sda2 on /usr/share/nginx/html type ext4 (rw,relatime,data=ordered)/dev/sda2 on /usr/share/nginx/html type ext4 (rw,relatime,data=ordered)
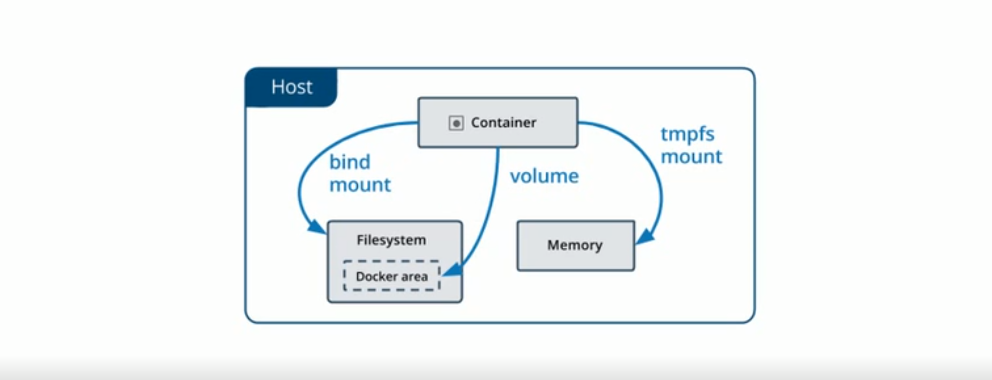
进入到容器内使用mount命令可以发现/dev/sda2 on /usr/share/nginx/html type ext4 (rw,relatime,data=ordered)已经挂载了
docker run -itd --name=nginx-test -v /app/wwwroot:/usr/share/nginx/html nginx
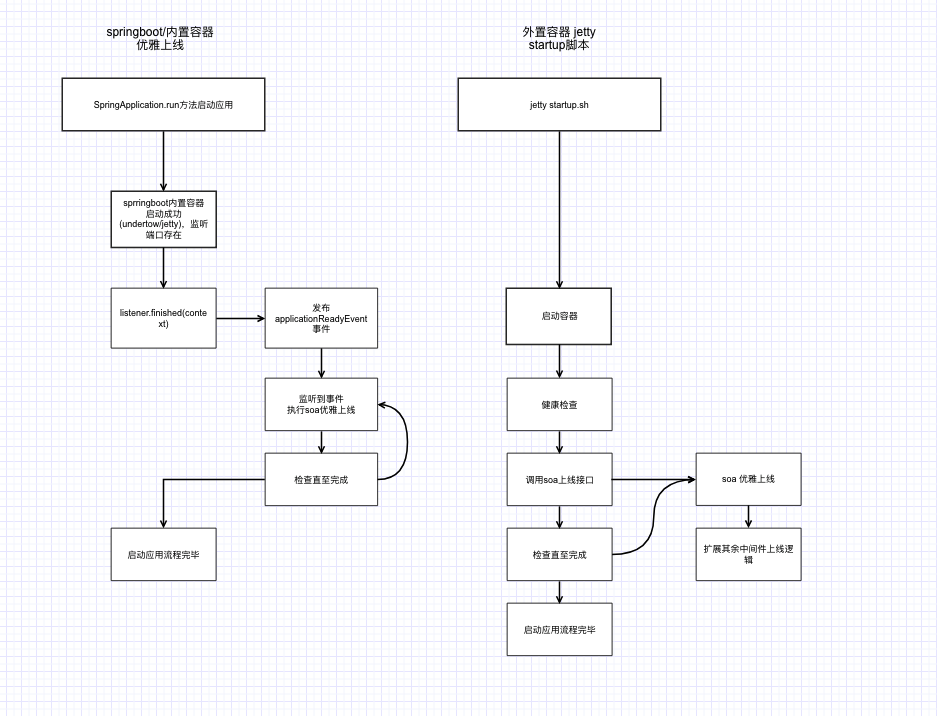
参看sofa-boot的健康检查的源码,它会在程序启动的时候先对springboot的组件做一些健康检查,然后再对它自己搞得sofa的一些中间件做健康检查,整个健康检查的流程完毕之后(sofaboot 目前是没法对自身应用层面做健康检查的,它有写相关接口,但是写死了port is ready…)才会暴露服务或者说优雅上线,那么它健康检查的时机是什么时候呢: