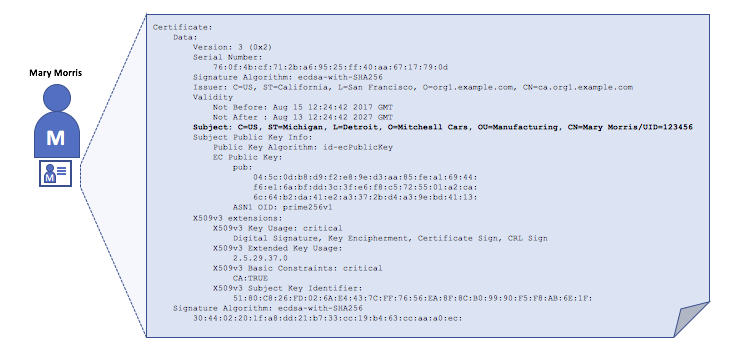
1|什么是JWT ?
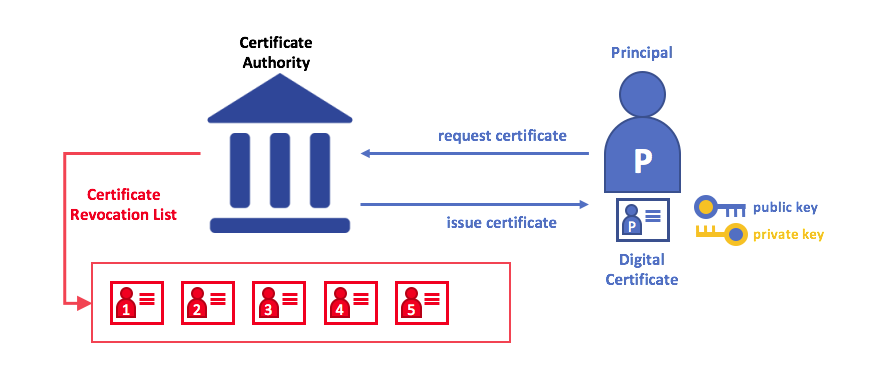
JWT,全称Json Web Token,用于作为JSON对象在各方之间安全地传输信息。该信息可以被验证和信任,因为它是数字签名的。
1|与Session的区别
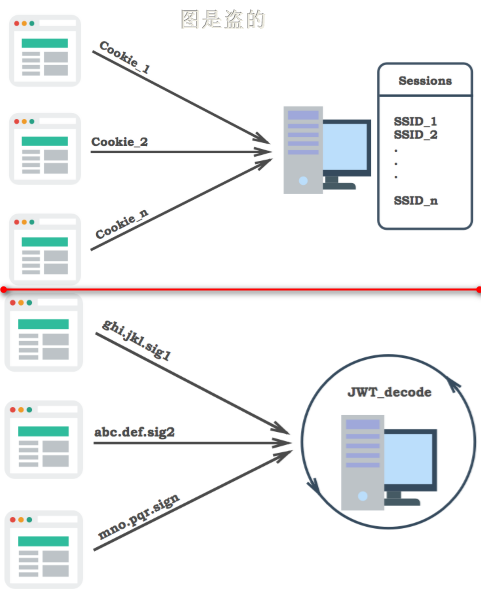
一、Session是在服务器端的,而JWT是在客户端的,这点很重要。
二、流程不同
1|JWT使用场景
- 大量需要进行跨域的站点
- 服务器运算能力较差、存储空间较小
1|JWT的原理
JWT 的原理是,服务器认证以后,生成一个 JSON 对象,发回给用户,就像下面这样。
{
"姓名": "张三",
"角色": "管理员",
"到期时间": "2018年7月1日0点0分"
}
以后,用户与服务端通信的时候,都要发回这个 JSON 对象。服务器完全只靠这个对象认定用户身份。为了防止用户篡改数据,服务器在生成这个对象的时候,会加上签名(详见后文)。
服务器就不保存任何 session 数据了,也就是说,服务器变成无状态了,从而比较容易实现扩展。
1|JWT数据的格式
实际的 JWT 大概就像下面这样。
它是一个很长的字符串,中间用点(.)分隔成三个部分。注意,JWT 内部是没有换行的,这里只是为了便于展示,将它写成了几行。
JWT 的三个部分依次如下。
- Header(头部)
- Payload(负载)
- Signature(签名)
Header 部分是一个 JSON 对象,描述 JWT 的元数据,通常是下面的样子。
{
"alg": "HS256",
"typ": "JWT"
}
上面代码中,alg属性表示签名的算法(algorithm),默认是 HMAC SHA256(写成 HS256);typ属性表示这个令牌(token)的类型(type),JWT 令牌统一写为JWT。
最后,将上面的 JSON 对象使用 Base64URL 算法(详见后文)转成字符串。
Payload
Payload 部分也是一个 JSON 对象,用来存放实际需要传递的数据。JWT 规定了7个官方字段,供选用。
- iss (issuer):签发人
- exp (expiration time):过期时间
- sub (subject):主题
- aud (audience):受众
- nbf (Not Before):生效时间
- iat (Issued At):签发时间
- jti (JWT ID):编号
除了官方字段,你还可以在这个部分定义私有字段,下面就是一个例子。
{
"sub": "1234567890",
"name": "John Doe",
"admin": true
}
注意,JWT 默认是不加密的,任何人都可以读到,所以不要把秘密信息放在这个部分。
这个 JSON 对象也要使用 Base64URL 算法转成字符串。
Signature
Signature 部分是对前两部分的签名,防止数据篡改。
首先,需要指定一个密钥(secret)。这个密钥只有服务器才知道,不能泄露给用户。然后,使用 Header 里面指定的签名算法(默认是 HMAC SHA256),按照下面的公式产生签名。
HMACSHA256( base64UrlEncode(header) + "." + base64UrlEncode(payload), secret)
算出签名以后,把 Header、Payload、Signature 三个部分拼成一个字符串,每个部分之间用”点”(.)分隔,就可以返回给用户。
Base64URL
前面提到,Header 和 Payload 串型化的算法是 Base64URL。这个算法跟 Base64 算法基本类似,但有一些小的不同。
JWT 作为一个令牌(token),有些场合可能会放到 URL(比如 api.example.com/?token=xxx)。Base64 有三个字符+、/和=,在 URL 里面有特殊含义,所以要被替换掉:=被省略、+替换成-,/替换成_ 。这就是 Base64URL 算法。
1|JWT的使用方式
客户端收到服务器返回的 JWT,可以储存在 Cookie 里面,也可以储存在 localStorage。
此后,客户端每次与服务器通信,都要带上这个 JWT。你可以把它放在 Cookie 里面自动发送,但是这样不能跨域,所以更好的做法是放在 HTTP 请求的头信息Authorization字段里面。
Authorization: Bearer <token>
另一种做法是,跨域的时候,JWT 就放在 POST 请求的数据体里面。
1|JWT 的几个特点
(1)JWT 默认是不加密,但也是可以加密的。生成原始 Token 以后,可以用密钥再加密一次。
(2)JWT 不加密的情况下,不能将秘密数据写入 JWT。
(3)JWT 不仅可以用于认证,也可以用于交换信息。有效使用 JWT,可以降低服务器查询数据库的次数。
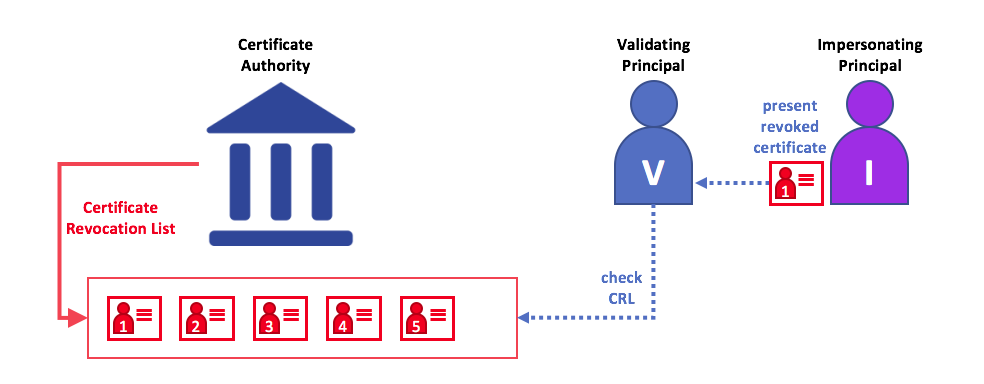
(4)JWT 的最大缺点是,由于服务器不保存 session 状态,因此无法在使用过程中废止某个 token,或者更改 token 的权限。也就是说,一旦 JWT 签发了,在到期之前就会始终有效,除非服务器部署额外的逻辑。
(5)JWT 本身包含了认证信息,一旦泄露,任何人都可以获得该令牌的所有权限。为了减少盗用,JWT 的有效期应该设置得比较短。对于一些比较重要的权限,使用时应该再次对用户进行认证。
(6)为了减少盗用,JWT 不应该使用 HTTP 协议明码传输,要使用 HTTPS 协议传输。
1|内容说明
以上主要内容转载于廖雪峰的网络日志
2|0实例:使用Django完成微信小程序的JWT登录及鉴权
网上目前已经有了一些文章来说明了,可是我在查阅的时候发现大多讲得不是很清楚。
2|1基本了解
通过之前的内容铺垫,相信读者对于JWT都有了一定的了解,总的来说,便是JWT是保存在用户端的Token机制。
需要注意的是:JWT默认是无加密的,只是使用了一层Base64编码,所以我们不能将重要信息,如密码等放入header和payload字段中。
2|2开始
对于Django来说,这里我们使用djangorestframework-jwt库
安装命令:
pip install djangorestframework-jwt
注意djangorestframework-jwt库默认将settings里的SECRET_KEY当中jwt加密秘钥。
首先我们先去我们的project下的settings文件内设置jwt库的一些参数
import datetime
# 在末尾添加上
REST_FRAMEWORK = {
'DEFAULT_AUTHENTICATION_CLASSES': (
'rest_framework_jwt.authentication.JSONWebTokenAuthentication',# JWT认证,在前面的认证方案优先
'rest_framework.authentication.SessionAuthentication',
'rest_framework.authentication.BasicAuthentication',
),
}
JWT_AUTH = {
'JWT_EXPIRATION_DELTA': datetime.timedelta(days=1), #JWT_EXPIRATION_DELTA 指明token的有效期
}
登录函数的实现:
'''
登录函数:
'''
def get_user_info_func(user_code):
api_url = 'https://api.weixin.qq.com/sns/jscode2session?appid={0}&secret={1}&js_code={2}&grant_type=authorization_code'
get_url = api_url.format(App_id,App_secret,user_code)
r = requests.get(get_url)
return r.json()
@require_http_methods(['POST'])
def user_login_func(request):
try:
user_code = request.POST.get('user_code')
print(user_code)
if user_code == None:
print(request.body)
json_data = json.loads(request.body)
user_code = json_data['user_code']
print(user_code)
except:
return JsonResponse({'status':500,'error':'请输入完整数据'})
try:
json_data = get_user_info_func(user_code)
#json_data = {'errcode':0,'openid':'111','session_key':'test'}
if 'errcode' in json_data:
return JsonResponse({'status': 500, 'error': '验证错误:' + json_data['errmsg']})
res = login_or_create_account(json_data)
return JsonResponse(res)
except:
return JsonResponse({'status':500,'error':'无法与微信验证端连接'})
def login_or_create_account(json_data):
openid = json_data['openid']
session_key = json_data['session_key']
try:
user = User.objects.get(username=openid)
except:
user = User.objects.create(
username=openid,
password=openid,
)
user.session_key = session_key
user.save()
try:
jwt_payload_handler = api_settings.JWT_PAYLOAD_HANDLER
jwt_encode_handler = api_settings.JWT_ENCODE_HANDLER
payload = jwt_payload_handler(user)
token = jwt_encode_handler(payload)
res = {
'status': 200,
'token': token
}
except:
res = {
'status': 500,
'error': 'jwt验证失败'
}
return res
视图函数:
'''
视图样例:
'''
from django.http import JsonResponse
from account.models import *
from rest_framework_jwt.views import APIView
from rest_framework import authentication
from rest_framework.permissions import IsAuthenticated
from rest_framework_jwt.authentication import JSONWebTokenAuthentication
from rest_framework import permissions
class IsOwnerOrReadOnly(permissions.BasePermission):
def has_object_permission(self, request, view, obj):
if request.method in ['GET','POST']:
return True
return obj.user == request.user
class test_view(APIView):
http_method_names = ['post'] #限制api的访问方式
authentication_classes = (authentication.SessionAuthentication,JSONWebTokenAuthentication)
permission_classes = (IsAuthenticated,IsOwnerOrReadOnly) #权限管理
def post(self,request): #视图函数
user = request.user.username
U = User.objects.get(username=user)
json_data = json.loads(request.body)
try:
test = json_data['']
except:
return JsonResponse({'status':500,'errmsg':'参数不全'})
try:
U.sex = sex
U.weight = weight
U.height = height
U.save()
except:
return JsonResponse({'status': 500, 'errmsg': '数据库错误'})
return JsonResponse({'status':200})
urls.py:
urlpatterns = [
re_path('^$', index),
re_path('^login$',login), # 登录
re_path('^test$',test_view.as_view())
]