Keepalived-Redis(主从高可用)方案
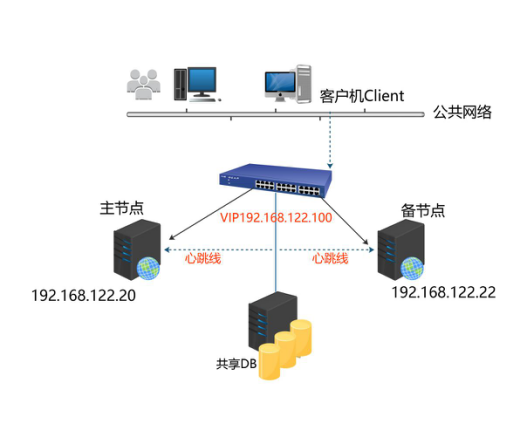
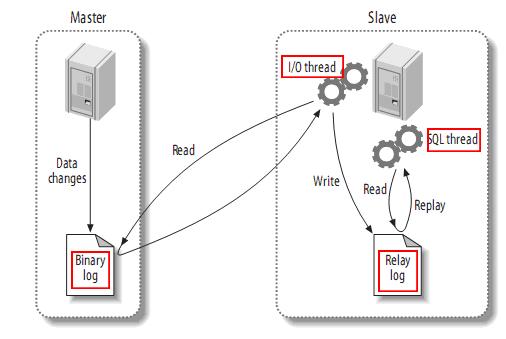
当系统中只有一台redis运行时,一旦该redis挂了,会导致整个系统无法运行,所以想到的办法自然就是备份。一台redis出现问题了,另一台redis可以继续提供服务。但由于redis目前只支持主从复制备份(不支持主主复制),当主redis挂了,从redis只能提供读服务,无法提供写服务。所以,还得想办法,当主redis挂了,我们让从redis升级成为主redis。这就需要自动故障转移,keepalived可以实现redis的双机热备作为过渡方案。
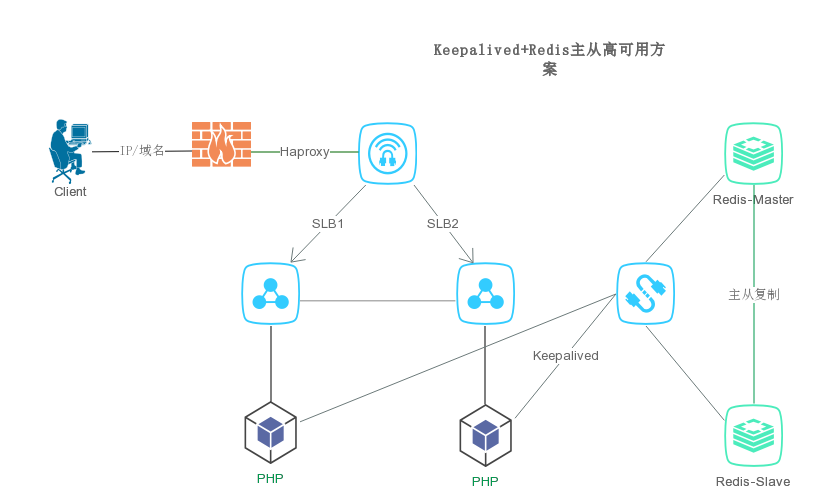
环境说明:
操作系统:CentOS release 6.8 (64)
Master IP:192.168.129.132
Slave IP:192.168.129.133
Virtural IP : 192.168.129.100
Redis Version: 3.2.28
Keepalived v1.2.13
前期准备:
1、下载包到/usr/local/src目录,配置yum源
curl -o /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-6.repo
wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-6.repo
yum makecahce
yum install -y gcc openssl-devel kernel-devel
2、修改Hostname主机名,关闭selinux和iptables
[root@localhost ~]# sed -i 's@SELINUX=enforcing@SELINUX=disabled@g' /etc/selinux/config
[root@localhost ~]# setenforce 0
[root@localhost ~]# /etc/init.d/iptables stop
3、分别修改两台主机名为redis_master 和 redis_slave
[root@localhost ~]# vim /etc/sysconfig/network
HOSTNAME=redis_master
[root@localhost ~]# vim /etc/sysconfig/network
HOSTNAME=redis_slave
4、禁用大内存页面,详细请了解此篇文章
http://blog.csdn.net/longwang155069/article/details/50897026
[root@redis_master ~]# echo 'never' > /sys/kernel/mm/transparent_hugepage/enabled
[root@redis_master ~]# vi /etc/sysctl.conf #编辑,在最后一行添加下面代码
vm.overcommit_memory = 1
[root@redis_master ~]# sysctl -p #使设置立即生效
Redis主从搭建
详细步骤
#下载Redis,两台机器都需要做相同操作
[root@redis_master ~]# wget http://download.redis.io/releases/redis-3.2.8.tar.gz
#解压
[root@redis_master ~]# tar -zxvf redis-3.2.8.tar.gz
[root@redis_master ~]# cd redis-3.2.8
[root@redis_master ~]# make
[root@redis_master ~]# make install PREFIX=/usr/local/redis
mkdir /usr/local/redis/etc
#下载配置文件和启动脚本
wget http://soft.8090st.com/conf/redis.conf -O /usr/local/redis/etc/redis.conf
wget http://soft.8090st.com/shell/redis.sh -O /etc/init.d/redis
#添加redis用户
useradd -s /sbin/nologin redis
mkdir /usr/local/redis/var
chmod 777 /usr/local/redis/var
chmod 755 /etc/init.d/redis
chkconfig --add redis
chkconfig redis on
#启动redis测试是否正常
service redis start

#redis主从配置文件
①、主redis需要修改的文件及内容
[root@redis_master ~]# vi /usr/local/redis/etc/redis.conf
bind 0.0.0.0
其余都可以安装默认状态
②、从redis需要修改的文件及内容
[root@redis_slave ~]# vi /usr/local/redis/etc/redis.conf
bind 0.0.0.0
slaveof 192.168.129.132 6379 //指定主redis的地址与端口
如果master设置了验证密码,还需配置masterauth。如果master设置了验证密码为admin,应当配置masterauth admin。
配置完之后重新启动slave的Redis服务,OK,主从配置完成。下面测试一下:
在master和slave分别执行info命令,查看结果如下:
# 查看主从状态
Redis主
[root@redis_master ~]# redis-cli info |grep role -A 3

Redis从
[root@redis_slave ~]# ../bin/redis-cli info |grep role -A 3

测试现在redis主从是否同步数据
[root@redis_master bin]# redis-cli
127.0.0.1:6379> set a a
OK
在从上get查看a的值,结果和redis主的值相同。
[root@redis_slave bin]# redis-cli
127.0.0.1:6379> get a
"a"
在Redis从服务器上试试能不能插入数据。
redis-cli -p 6379 set hello world
(error) READONLY You can’t write against a read only slave.
成功配置主从redis服务器,由于配置中有一条从服务器是只读的,所以从服务器没法设置数据,只可以读取数据。
安装过程错误解决方法
zmalloc.h:50:31: error: jemalloc/jemalloc.h: No such file or directory
zmalloc.h:55:2: error: #error “Newer version of jemalloc required”
make[1]: *** [adlist.o] Error 1
#make MALLOC=libc
1. 安装和配置keepalived
在Master和Slave上安装Keepalived
这里以yum安装为例
$ yum install -y keepalived
keepalived安装完成后,我们需要修改它的配置文件:
首先,在Master上创建如下配置文件:
$ mv /etc/keepalived/keepalived.conf /etc/keepalived/keepalived.conf_bak
$ > /etc/keepalived/keepalived.conf
$ vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id redis100
}
vrrp_script chk_redis
{
script “/etc/keepalived/scripts/redis_check.sh 127.0.0.1 6379”
interval 2
timeout 2
fall 3
}
vrrp_instance redis {
state MASTER # master set to SLAVE also
interface eth0
virtual_router_id 50
priority 150
nopreempt # no seize,must add
advert_int 1
authentication { #all node must same
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.129.100/24 //定义虚拟浮动IP
}
track_script {
chk_redis
}
notify_master “/etc/keepalived/scripts/redis_master.sh 192.168.129.133 6379"
notify_backup “/etc/keepalived/scripts/redis_backup.sh 192.168.129.133 6379"
notify_fault /etc/keepalived/scripts/redis_fault.sh
notify_stop /etc/keepalived/scripts/redis_stop.sh
}
//192.168.129.133 定义redis从服务器IP
//interface eth0 定义网卡名称,有的网卡名不相同,请自行修改
然后,在Slave上创建如下配置文件:
! Configuration File for keepalived
global_defs {
router_id redis101
}
vrrp_script chk_redis
{
script “/etc/keepalived/scripts/redis_check.sh 127.0.0.1 6379”
interval 2
timeout 2
fall 3
}
vrrp_instance redis {
state BACKUP
interface eth0
virtual_router_id 50
priority 100
advert_int 1
authentication { #all node must same
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.0.200/24
}
track_script {
chk_redis
}
notify_master “/etc/keepalived/scripts/redis_master.sh 192.168.129.132 6379"
notify_backup “/etc/keepalived/scripts/redis_backup.sh 192.168.129.132 6379"
notify_fault /etc/keepalived/scripts/redis_fault.sh
notify_stop /etc/keepalived/scripts/redis_stop.sh
}
//192.168.129.132 定义redis主服务器IP
//interface eth0 定义网卡名称,有的网卡名不相同,请自行修改
在Master和Slave上创建监控Redis的脚本
$ mkdir /etc/keepalived/scripts
$ vim /etc/keepalived/scripts/redis_check.sh
#!/bin/bash
ALIVE=`/usr/local/redis/bin/redis-cli -h $1 -p $2 PING`
LOGFILE="/var/log/keepalived-redis-check.log"
echo "[CHECK]" >> $LOGFILE
date >> $LOGFILE
if [ $ALIVE == "PONG" ]; then :
echo "Success: redis-cli -h $1 -p $2 PING $ALIVE" >> $LOGFILE 2>&1
exit 0
else
echo "Failed:redis-cli -h $1 -p $2 PING $ALIVE " >> $LOGFILE 2>&1
exit 1
fi
编写以下负责运作的关键脚本:
notify_master /etc/keepalived/scripts/redis_master.sh
notify_backup /etc/keepalived/scripts/redis_backup.sh
notify_fault /etc/keepalived/scripts/redis_fault.sh
notify_stop /etc/keepalived/scripts/redis_stop.sh
因为Keepalived在转换状态时会依照状态来呼叫:
当进入Master状态时会呼叫notify_master
当进入Backup状态时会呼叫notify_backup
当发现异常情况时进入Fault状态呼叫notify_fault
当Keepalived程序终止时则呼叫notify_stop
首先,在Redis Master上创建notity_master与notify_backup脚本:
$ vim /etc/keepalived/scripts/redis_master.sh
#!/bin/bash
REDISCLI="/usr/local/redis/bin/redis-cli -h $1 -p $3"
LOGFILE="/var/log/keepalived-redis-state.log"
echo "[master]" >> $LOGFILE
date >> $LOGFILE
echo "Being master...." >> $LOGFILE 2>&1
echo "Run MASTER cmd ..." >> $LOGFILE 2>&1
$REDISCLI SLAVEOF $2 $3 >> $LOGFILE
sleep 10 #delay 10 s wait data async cancel sync
echo "Run SLAVEOF NO ONE cmd ..." >> $LOGFILE
$REDISCLI SLAVEOF NO ONE >> $LOGFILE 2>&1
$ vim /etc/keepalived/scripts/redis_backup.sh
#!/bin/bash
REDISCLI="/usr/local/redis/bin/redis-cli"
LOGFILE="/var/log/keepalived-redis-state.log"
echo "[backup]" >> $LOGFILE
date >> $LOGFILE
echo "Run SLAVEOF cmd ..." >> $LOGFILE
$REDISCLI SLAVEOF $2 $3 >> $LOGFILE 2>&1
# echo "Being slave...." >> $LOGFILE 2>&1
sleep 15 #delay 15 s wait data sync exchange role
接着,在Redis Slave上创建notity_master与notify_backup脚本:
$ vim /etc/keepalived/scripts/redis_master.sh
#!/bin/bash
REDISCLI="/usr/local/redis/bin/redis-cli -h $1 -p $3"
LOGFILE="/var/log/keepalived-redis-state.log"
echo "[master]" >> $LOGFILE
date >> $LOGFILE
echo "Being master...." >> $LOGFILE 2>&1
echo "Run SLAVEOF cmd ... " >> $LOGFILE
$REDISCLI SLAVEOF $2 $3 >> $LOGFILE 2>&1
#echo "SLAVEOF $2 cmd can't excute ... " >> $LOGFILE
sleep 10 ##delay 15 s wait data sync exchange role
echo "Run SLAVEOF NO ONE cmd ..." >> $LOGFILE
$REDISCLI SLAVEOF NO ONE >> $LOGFILE 2>&1
$ vim /etc/keepalived/scripts/redis_backup.sh
#!/bin/bash
REDISCLI="/usr/local/redis/bin/redis-cli"
LOGFILE="/var/log/keepalived-redis-state.log"
echo "[BACKUP]" >> $LOGFILE
date >> $LOGFILE
echo "Being slave...." >> $LOGFILE 2>&1
echo "Run SLAVEOF cmd ..." >> $LOGFILE 2>&1
$REDISCLI SLAVEOF $2 $3 >> $LOGFILE
sleep 100 #delay 10 s wait data async cancel sync
exit(0)
然后在Master与Slave创建如下相同的脚本:
$ vim /etc/keepalived/scripts/redis_fault.sh
#!/bin/bash
LOGFILE=/var/log/keepalived-redis-state.log
echo "[fault]" >> $LOGFILE
date >> $LOGFILE
$ vim /etc/keepalived/scripts/redis_stop.sh
#!/bin/bash
LOGFILE=/var/log/keepalived-redis-state.log
echo "[stop]" >> $LOGFILE
date >> $LOGFILE
给脚本都加上可执行权限:
(这点很重要,最开始由于这不没做,运行后一直报错 “VRRP_Instance(Redis) Now in FAULT state”)
$ chmod +x /etc/keepalived/scripts/*.sh
脚本创建完成以后,我们开始按照如下流程进行测试:
1.启动Master上的Redis
[root@redis_master ~]# /etc/init.d/redis start
Starting redis-server: [ OK ]
2.启动Slave上的Redis
[root@redis_slave ~]# /etc/init.d/redis start
Starting redis-server: [ OK ]
3.启动Master上的Keepalived
[root@redis_master ~]# /etc/init.d/keepalived start
Starting keepalived: [ OK ]
启动后我们看下eth0这张网卡是否有VIP
[root@redis_master ~]# ip a

4.启动Slave上的Keepalived
[root@redis_slave ~]# /etc/init.d/keepalived start
Starting keepalived: [ OK ]
5.客户机尝试通过VIP连接Redis:
[root@localhost ~]# redis-cli -h 192.168.129.100 INFO |grep role -A 3

从图中我们可以看出当前从机器是192.168.129.133
6.尝试插入一些数据:
$ redis-cli -h 192.168.129.100 SET Hello Redis

从VIP读取数据
$ redis-cli -h 192.168.129.100 GET Hello

从Master读取数据
$ redis-cli -h 192.168.129.132 GET Hello
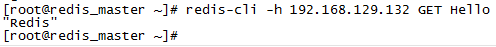
从Slave读取数据
$ redis-cli -h 192.168.129.133 GET Hello

接下来模拟故障产生:
将Master上的Redis停了
$ service redis stop
查看Master上的Keepalived日志
$ tailf /var/log/keepalived-redis-state.log
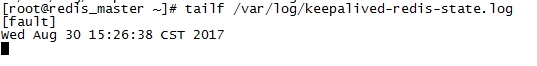
同时Slave上的日志显示:
$ tailf /var/log/keepalived-redis-state.log
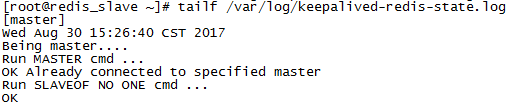
然后我们可以发现,Slave已经接管服务,并且担任Master的角色了。
$ redis-cli -h 192.168.129.100 INFO
然后我们恢复Master的Redis进程
$ service redis start
查看Master上的Keepalived日志
$ tailf /var/log/keepalived-redis-state.log
同时Slave上的日志显示:
$ tailf /var/log/keepalived-redis-state.log

可以发现目前的Master已经再次恢复了Master的角色,故障切换以及自动恢复都成功了。
注意事项:主从的redis都要开启持续化本地备份,否则数据会丢失。
1.master slave IP、VIP位于同一个vlan
2. interface 网卡名称配置正确
3. virtual_router_id VRRP 的Id 不能与vlan 其他设备使用的冲突
4.配置2s检测一次,3次都失败才认为要切换